-
강화학습 기초 - 강화학습, 벨만 방정식전공 - AI/강화학습 2023. 9. 24. 15:23

유데미 강의를 참고하여 글을 작성하였습니다
목차
1. 강화학습2. 벨만 방정식
강화학습
강화학습(Reinforcement learning)은 머신러닝의 한 종류로, 행동을 수행하는 학습자가 어떤 행동을 해야 하는지 알지 못하는 상태에서 행동에 대한 보상을 극대화하기 위해 어떻게 행동해야 할지 방향을 찾는 학습 방법이다
가상의 학습공간을 환경이라고 하고 가상의 학습공간에서 우리를 대신해 학습을 할 대상을 대리인이라 한다
위와 같은 미로가 있고 성공으로 들어가면 +1, 실패로 들어가면 -1 이라는 최종 보상을 받는다고 가정하자
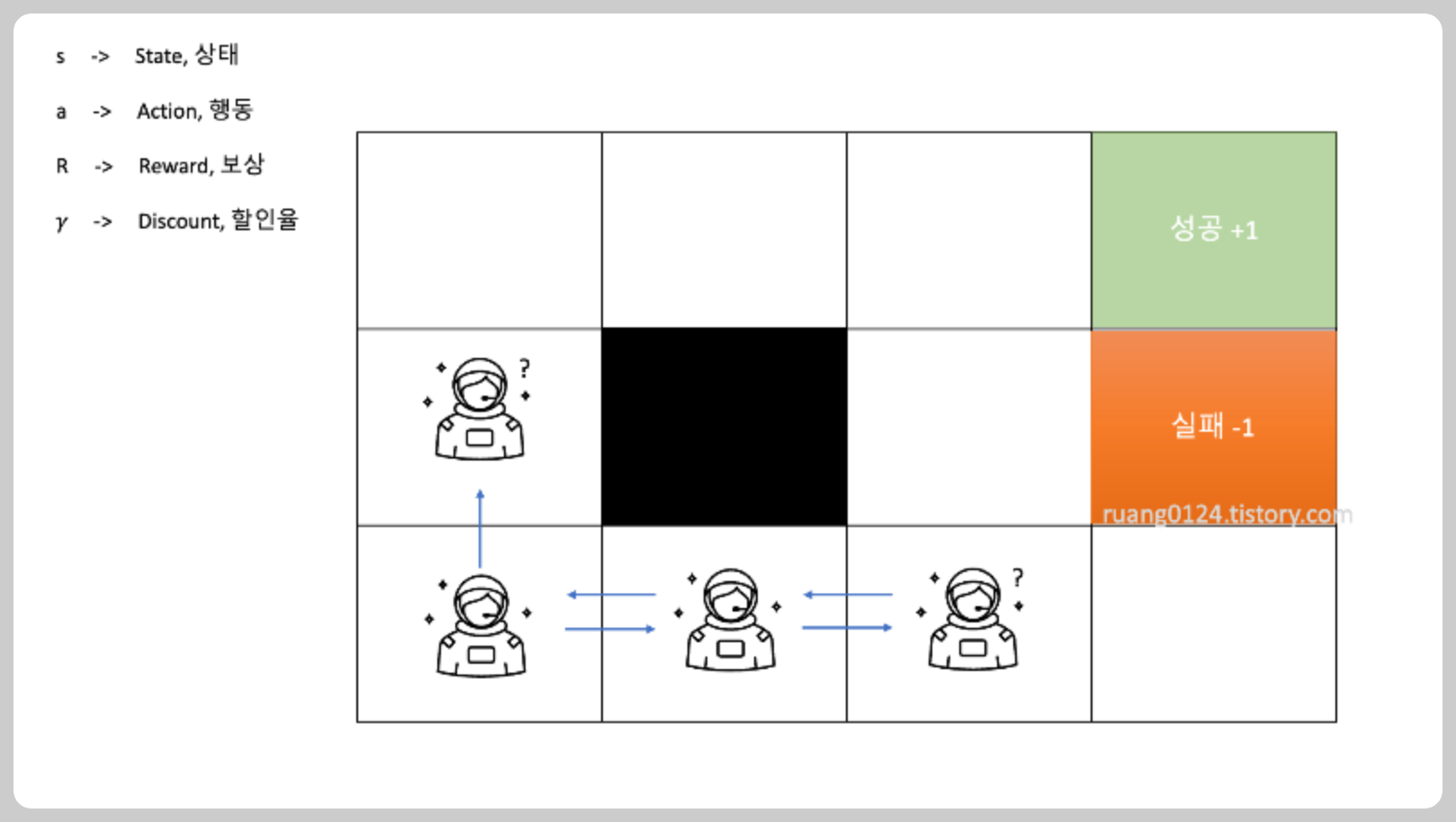
대리인은 지금 여기가 어디인지 아무것도 모르는 상태이기 때문에 왼쪽으로 갔다 오른쪽으로 갔다 위로 갔다 열심히 탐색을 한다

열심히 탐색을 하는데 우연히 위의 경로로 이동을 했고 성공으로 들어가 +1점을 얻었다

위의 그림에 있는 위치로 가서 오른쪽으로 1칸 이동하면 +1점을 얻을 수 있다

방법이 어떻든 저 위치로 이동하고 오른쪽으로 가면 +1점을 획득할 수 있으므로
빨간색 화살표가 있는 위치의 가치를 1이라고 하겠다
그렇다면 저 위치로 이동하기 전의 위치는 위와 같이 빨간색 화살표가 위치해있는 곳이다

위와 같이 이 전의 위치를 모두 찾아 1이라는 가치를 저장했다
다음에 길을 찾아갈때 이 길을 이용하면 될 것이다
이렇게 대리인이 환경에 대해 학습을 진행하면서 성공에 도착해 보상을 최대화할 수 있다
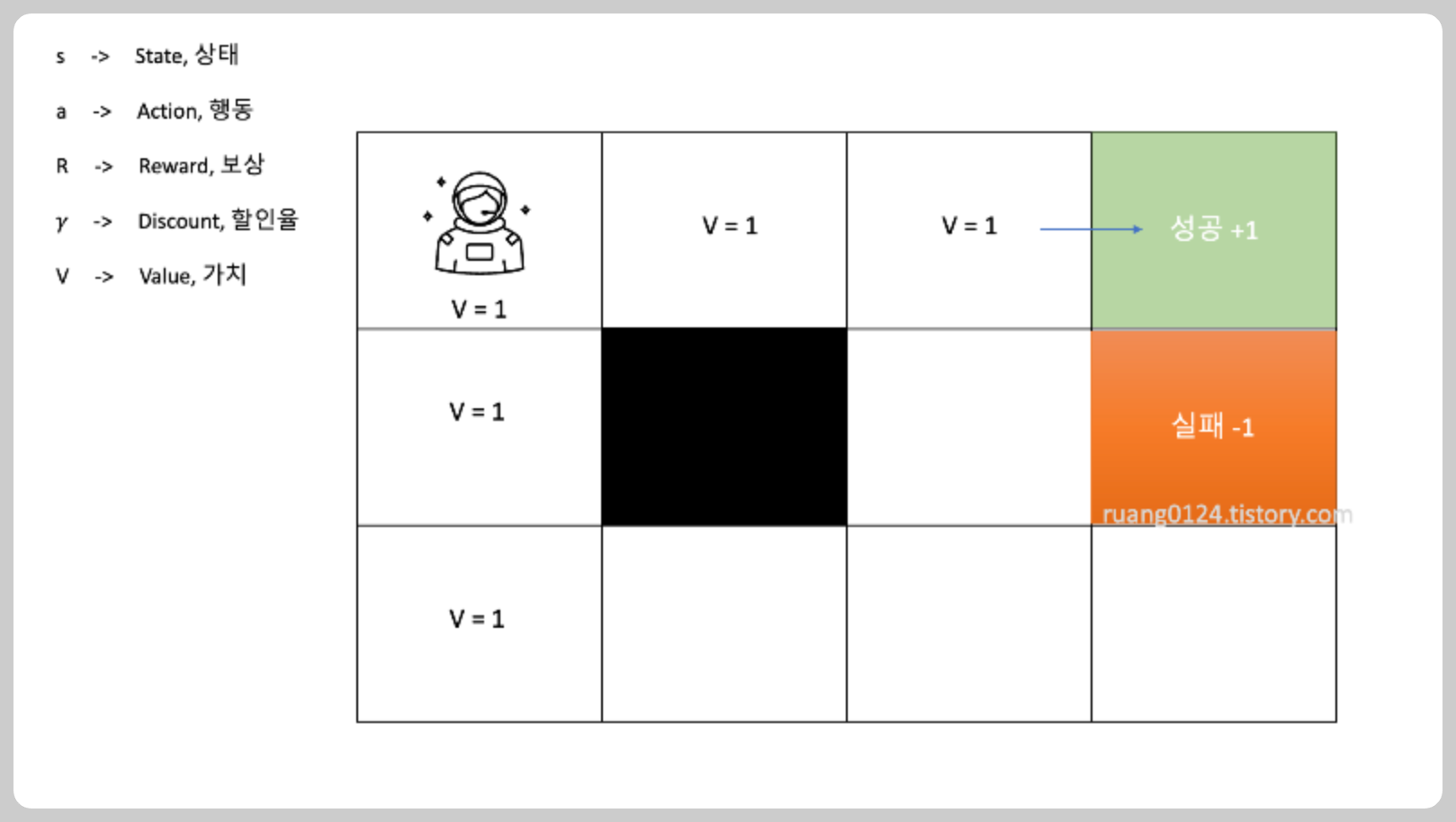
하지만 처음에 시작했던 위치가 아닌 다른 위치에서 시작한다면 어떻게 될까?

우리의 대리인은 어디로 가야 할지 정하지 못하게 된다
벨만 방정식
벨만방정식은 현재시점에서의 가치와 다음시점에서의 가치를 다루는 함수이다
R(s, a)는 현재상태에서 a 라는 행동을 했을 때의 보상이고, 다음상태에 감마값을 곱했을 때의 최댓값을 구한다

위에서 우리는 모든 경로에 V=1 이라는 가치를 부여했다
하지만 시작지점이 달라지니 대리인은 어디로 이동해야 할지 모르는 문제가 생겼다
이 문제를 해결하기 위해 감마가 추가되었다

V=1을 기준으로 0.9씩 곱해서 가치를 부여하면 위와 같은 가치가 부여된다
시작점이 변경되어도 가치가 높은 쪽으로 이동하면 길을 쉽게 찾을 수 있게 된다

위와 같은 경우 실패로 들어갈 수 있지만 위로갈 확률이 더 크다고 할 수 있다

이렇게 벨만 방정식을 이용해 가치를 다르게 함으로써 어느 위치에서 시작하든 가치가 최대가 되는 방향으로 이동하게 할 수 있다
728x90'전공 - AI > 강화학습' 카테고리의 다른 글
강화학습 - MC, SARSA (0) 2023.10.22 강화학습 - MDP, MP (0) 2023.10.22 강화학습 기초 - 경사하강법, 확률적 경사하강법, 역전파 (0) 2023.09.24 강화학습 기초 - 신경망 작동 방법, 신경망 학습 방법 (0) 2023.09.24 강화학습 기초 - 뉴런, 활성화 함수 (0) 2023.09.24
